Browse by signal
Fast keyword tagging derived from titles and summaries. Expect more nuance as we add model-assisted tagging.
Top results tagged #product

Black Friday is next week, and Costco has already launched some great early holiday deals on TVs, tablets, and more.

This new AI coding environment looks like a real winner. Here's why.

Anthropic released its most capable artificial intelligence model yet on Monday, slashing prices by roughly two-thirds while claiming state-of-the-art performance on software engineering tasks — a strategic move that intensifies the AI startup's competition with deep-pocketed rivals OpenAI and Google. The new model, Claude Opus 4.5 , scored higher on Anthropic's most challenging internal engineering assessment than any human job candidate in the company's history, according to materials reviewed by VentureBeat. The result underscores both the rapidly advancing capabilities of AI systems and growing questions about how the technology will reshape white-collar professions. The Amazon-backed company is pricing Claude Opus 4.5 at $5 per million input tokens and $25 per million output tokens — a dramatic reduction from the $15 and $75 rates for its predecessor, Claude Opus 4.1 , released earlier this year. The move makes frontier AI capabilities accessible to a broader swath of developers and enterprises while putting pressure on competitors to match both performance and pricing. "We want to make sure this really works for people who want to work with these models," said Alex Albert, Anthropic's head of developer relations, in an exclusive interview with VentureBeat. "That is really our focus: How can we enable Claude to be better at helping you do the things that you don't necessarily want to do in your job?" The announcement comes as Anthropic races to maintain its position in an increasingly crowded field. OpenAI recently released GPT-5.1 and a specialized coding model called Codex Max that can work autonomously for extended periods. Google unveiled Gemini 3 just last week, prompting concerns even from OpenAI about the search giant's progress, according to a recent report from The Information. Opus 4.5 demonstrates improved judgment on real-world tasks, developers say Anthropic's internal testing revealed what the company describes as a qualitative leap in Claude Opus 4.5's reasoning capabilities. The model achieved 80.9% accuracy on SWE-bench Verified , a benchmark measuring real-world software engineering tasks, outperforming OpenAI's GPT-5.1-Codex-Max (77.9%), Anthropic's own Sonnet 4.5 (77.2%), and Google's Gemini 3 Pro (76.2%), according to the company's data. The result marks a notable advance over OpenAI's current state-of-the-art model, which was released just five days earlier. But the technical benchmarks tell only part of the story. Albert said employee testers consistently reported that the model demonstrates improved judgment and intuition across diverse tasks — a shift he described as the model developing a sense of what matters in real-world contexts. "The model just kind of gets it," Albert said. "It just has developed this sort of intuition and judgment on a lot of real world things that feels qualitatively like a big jump up from past models." He pointed to his own workflow as an example. Previously, Albert said, he would ask AI models to gather information but hesitated to trust their synthesis or prioritization. With Opus 4.5, he's delegating more complete tasks, connecting it to Slack and internal documents to produce coherent summaries that match his priorities. Opus 4.5 outscores all human candidates on company's toughest engineering test The model's performance on Anthropic's internal engineering assessment marks a notable milestone. The take-home exam, designed for prospective performance engineering candidates, is meant to evaluate technical ability and judgment under time pressure within a prescribed two-hour limit. Using a technique called parallel test-time compute — which aggregates multiple attempts from the model and selects the best result — Opus 4.5 scored higher than any human candidate who has taken the test, according to company. Without a time limit, the model matched the performance of the best-ever human candidate when used within Claude Code, Anthropic's coding environment. The company acknowledged that the test doesn't measure other crucial professional skills such as collaboration, communication, or the instincts that develop over years of experience. Still, Anthropic said the result "raises questions about how AI will change engineering as a profession." Albert emphasized the significance of the finding. "I think this is kind of a sign, maybe, of what's to come around how useful these models can actually be in a work context and for our jobs," he said. "Of course, this was an engineering task, and I would say models are relatively ahead in engineering compared to other fields, but I think it's a really important signal to pay attention to." Dramatic efficiency improvements cut token usage by up to 76% on key benchmarks Beyond raw performance, Anthropic is betting that efficiency improvements will differentiate Claude Opus 4.5 in the market. The company says the model uses dramatically fewer tokens — the units of text that AI systems process — to achieve similar or better outcomes compared to predecessors. At a medium effort level, Opus 4.5 matches the previous Sonnet 4.5 model's best score on SWE-bench Verified while using 76% fewer output tokens, according to Anthropic. At the highest effort level, Opus 4.5 exceeds Sonnet 4.5 performance by 4.3 percentage points while still using 48% fewer tokens. To give developers more control, Anthropic introduced an "effort parameter" that allows users to adjust how much computational work the model applies to each task — balancing performance against latency and cost. Enterprise customers provided early validation of the efficiency claims. "Opus 4.5 beats Sonnet 4.5 and competition on our internal benchmarks, using fewer tokens to solve the same problems," said Michele Catasta, president of Replit, a cloud-based coding platform, in a statement to VentureBeat. "At scale, that efficiency compounds." GitHub's chief product officer, Mario Rodriguez, said early testing shows Opus 4.5 "surpasses internal coding benchmarks while cutting token usage in half, and is especially well-suited for tasks like code migration and code refactoring." Early customers report AI agents that learn from experience and refine their own skills One of the most striking capabilities demonstrated by early customers involves what Anthropic calls "self-improving agents" — AI systems that can refine their own performance through iterative learning. Rakuten , the Japanese e-commerce and internet company, tested Claude Opus 4.5 on automation of office tasks. "Our agents were able to autonomously refine their own capabilities — achieving peak performance in 4 iterations while other models couldn't match that quality after 10," said Yusuke Kaji, Rakuten's general manager of AI for business. Albert explained that the model isn't updating its own weights — the fundamental parameters that define an AI system's behavior — but rather iteratively improving the tools and approaches it uses to solve problems. "It was iteratively refining a skill for a task and seeing that it's trying to optimize the skill to get better performance so it could accomplish this task," he said. The capability extends beyond coding. Albert said Anthropic has observed significant improvements in creating professional documents, spreadsheets, and presentations. "They're saying that this has been the biggest jump they've seen between model generations," Albert said. "So going even from Sonnet 4.5 to Opus 4.5, bigger jump than any two models back to back in the past." Fundamental Research Labs , a financial modeling firm, reported that "accuracy on our internal evals improved 20%, efficiency rose 15%, and complex tasks that once seemed out of reach became achievable," according to co-founder Nico Christie. New features target Excel users, Chrome workflows and eliminate chat length limits Alongside the model release, Anthropic rolled out a suite of product updates aimed at enterprise users. Claude for Excel became generally available for Max, Team, and Enterprise users with new support for pivot tables, charts, and file uploads. The Chrome browser extension is now available to all Max users. Perhaps most significantly, Anthropic introduced " infinite chats " — a feature that eliminates context window limitations by automatically summarizing earlier parts of conversations as they grow longer. "Within Claude AI, within the product itself, you effectively get this kind of infinite context window due to the compaction, plus some memory things that we're doing," Albert explained. For developers, Anthropic released "programmatic tool calling," which allows Claude to write and execute code that invokes functions directly. Claude Code gained an updated "Plan Mode" and became available on desktop in research preview, enabling developers to run multiple AI agent sessions in parallel. Market heats up as OpenAI, Google race to match performance and pricing Anthropic reached $2 billion in annualized revenue during the first quarter of 2025, more than doubling from $1 billion in the prior period. The number of customers spending more than $100,000 annually jumped eightfold year-over-year. The rapid release of Opus 4.5 — just weeks after Haiku 4.5 in October and Sonnet 4.5 in September — reflects broader industry dynamics. OpenAI released multiple GPT-5 variants throughout 2025, including a specialized Codex Max model in November that can work autonomously for up to 24 hours. Google shipped Gemini 3 in mid-November after months of development. Albert attributed Anthropic's accelerated pace partly to using Claude to speed its own development. "We're seeing a lot of assistance and speed-up by Claude itself, whether it's on the actual product building side or on the model research side," he said. The pricing reduction for Opus 4.5 could pressure margins while potentially expanding the addressable market. "I'm expecting to see a lot of startups start to incorporate this into their products much more and feature it prominently," Albert said. Yet profitability remains elusive for leading AI labs as they invest heavily in computing infrastructure and research talent. The AI market is projected to top $1 trillion in revenue within a decade, but no single provider has established dominant market position—even as models reach a threshold where they can meaningfully automate complex knowledge work. Michael Truell, CEO of Cursor, an AI-powered code editor, called Opus 4.5 "a notable improvement over the prior Claude models inside Cursor, with improved pricing and intelligence on difficult coding tasks." Scott Wu, CEO of Cognition, an AI coding startup, said the model delivers "stronger results on our hardest evaluations and consistent performance through 30-minute autonomous coding sessions." For enterprises and developers, the competition translates to rapidly improving capabilities at falling prices. But as AI performance on technical tasks approaches—and sometimes exceeds—human expert levels, the technology's impact on professional work becomes less theoretical. When asked about the engineering exam results and what they signal about AI's trajectory, Albert was direct: "I think it's a really important signal to pay attention to."
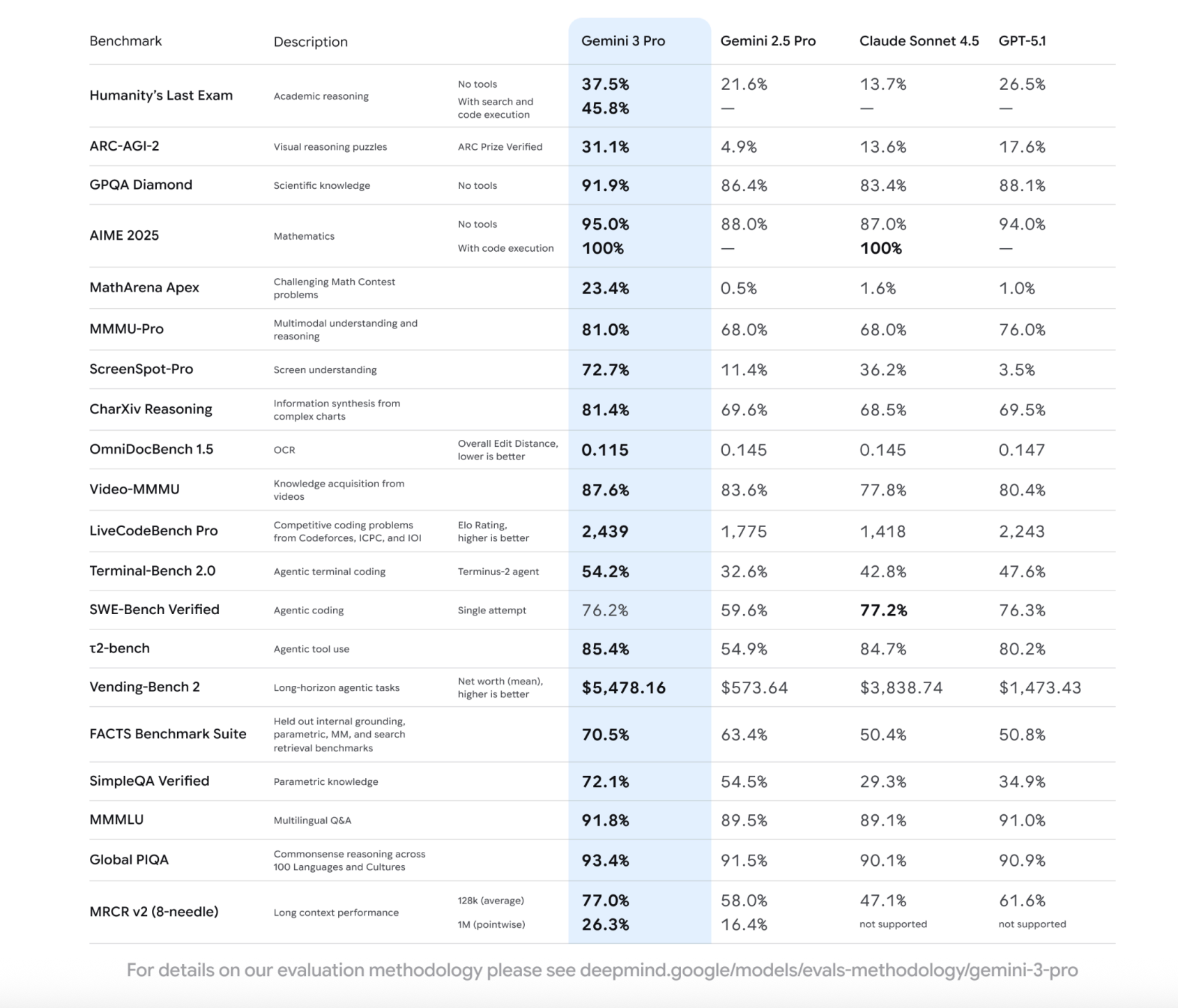
How do we move from language models that only answer prompts to systems that can reason over million token contexts, understand real world signals, and reliably act as agents on our behalf? Google just released Gemini 3 family with Gemini 3 Pro as the centerpiece that positions as a major step toward more general AI […] The post Google’s Gemini 3 Pro turns sparse MoE and 1M token context into a practical engine for multimodal agentic workloads appeared first on MarkTechPost .

Avatar director, known for his advocacy of new technology, told interviewer generative AI performance puts ‘all human experience into a blender’ Avatar director James Cameron has called AI actors “horrifying” and said what generative AI technology creates is “an average”. Cameron was speaking to CBS on Sunday Morning in the run-up to the release of the third Avatar film, subtitled Fire and Ash, and was asked about the pioneering technology he used in his film-making. After praising motion-capture performance as “a celebration of the actor-director moment”, Cameron expressed his disdain for artificial intelligence. “Go to the other end of the spectrum [from motion capture] and you’ve got generative AI, where they can make up a character. They can make up an actor. They can make up a performance from scratch with a text prompt. It’s like, no. That’s horrifying to me. That’s the opposite. That’s exactly what we’re not doing.” Continue reading...

In what appeared to be a bid to soak up some of Google's limelight prior to the launch of its new Gemini 3 flagship AI model — now recorded as the most powerful LLM in the world by multiple independent evaluators — Elon Musk's rival AI startup xAI last night unveiled its newest large language model, Grok 4.1. The model is now live for consumer use on Grok.com, social network X (formerly Twitter), and the company’s iOS and Android mobile apps, and it arrives with major architectural and usability enhancements, among them: faster reasoning, improved emotional intelligence, and significantly reduced hallucination rates. xAI also commendably published a white paper on its evaluations and including a small bit on training process here . Across public benchmarks, Grok 4.1 has vaulted to the top of the leaderboard, outperforming rival models from Anthropic, OpenAI, and Google — at least, Google's pre-Gemini 3 model (Gemini 2.5 Pro). It builds upon the success of xAI's Grok-4 Fast, which VentureBeat covered favorably shortly following its release back in September 2025. However, enterprise developers looking to integrate the new and improved model Grok 4.1 into production environments will find one major constraint: it's not yet available through xAI’s public API . Despite its high benchmarks, Grok 4.1 remains confined to xAI’s consumer-facing interfaces, with no announced timeline for API exposure. At present, only older models—including Grok 4 Fast (reasoning and non-reasoning variants), Grok 4 0709, and legacy models such as Grok 3, Grok 3 Mini, and Grok 2 Vision—are available for programmatic use via the xAI developer API. These support up to 2 million tokens of context, with token pricing ranging from $0.20 to $3.00 per million depending on the configuration. For now, this limits Grok 4.1’s utility in enterprise workflows that rely on backend integration, fine-tuned agentic pipelines, or scalable internal tooling. While the consumer rollout positions Grok 4.1 as the most capable LLM in xAI’s portfolio, production deployments in enterprise environments remain on hold. Model Design and Deployment Strategy Grok 4.1 arrives in two configurations: a fast-response, low-latency mode for immediate replies, and a “thinking” mode that engages in multi-step reasoning before producing output. Both versions are live for end users and are selectable via the model picker in xAI’s apps. The two configurations differ not just in latency but also in how deeply the model processes prompts. Grok 4.1 Thinking leverages internal planning and deliberation mechanisms, while the standard version prioritizes speed. Despite the difference in architecture, both scored higher than any competing models in blind preference and benchmark testing. Leading the Field in Human and Expert Evaluation On the LMArena Text Arena leaderboard , Grok 4.1 Thinking briefly held the top position with a normalized Elo score of 1483 — then was dethroned a few hours later with Google's release of Gemini 3 and its incredible 1501 Elo score. The non-thinking version of Grok 4.1 also fares well on the index, however, at 1465. These scores place Grok 4.1 above Google’s Gemini 2.5 Pro, Anthropic’s Claude 4.5 series, and OpenAI’s GPT-4.5 preview. In creative writing, Grok 4.1 ranks second only to Polaris Alpha (an early GPT-5.1 variant), with the “thinking” model earning a score of 1721.9 on the Creative Writing v3 benchmark. This marks a roughly 600-point improvement over previous Grok iterations. Similarly, in the Arena Expert leaderboard, which aggregates feedback from professional reviewers, Grok 4.1 Thinking again leads the field with a score of 1510. The gains are especially notable given that Grok 4.1 was released only two months after Grok 4 Fast, highlighting the accelerated development pace at xAI. Core Improvements Over Previous Generations Technically, Grok 4.1 represents a significant leap in real-world usability. Visual capabilities—previously limited in Grok 4—have been upgraded to enable robust image and video understanding, including chart analysis and OCR-level text extraction. Multimodal reliability was a pain point in prior versions and has now been addressed. Token-level latency has been reduced by approximately 28 percent while preserving reasoning depth. In long-context tasks, Grok 4.1 maintains coherent output up to 1 million tokens, improving on Grok 4’s tendency to degrade past the 300,000 token mark. xAI has also improved the model's tool orchestration capabilities. Grok 4.1 can now plan and execute multiple external tools in parallel, reducing the number of interaction cycles required to complete multi-step queries. According to internal test logs, some research tasks that previously required four steps can now be completed in one or two. Other alignment improvements include better truth calibration—reducing the tendency to hedge or soften politically sensitive outputs—and more natural, human-like prosody in voice mode, with support for different speaking styles and accents. Safety and Adversarial Robustness As part of its risk management framework, xAI evaluated Grok 4.1 for refusal behavior, hallucination resistance, sycophancy, and dual-use safety. The hallucination rate in non-reasoning mode has dropped from 12.09 percent in Grok 4 Fast to just 4.22 percent — a roughly 65% improvement. The model also scored 2.97 percent on FActScore, a factual QA benchmark, down from 9.89 percent in earlier versions. In the domain of adversarial robustness, Grok 4.1 has been tested with prompt injection attacks, jailbreak prompts, and sensitive chemistry and biology queries. Safety filters showed low false negative rates, especially for restricted chemical knowledge (0.00 percent) and restricted biological queries (0.03 percent). The model’s ability to resist manipulation in persuasion benchmarks, such as MakeMeSay, also appears strong—it registered a 0 percent success rate as an attacker. Limited Enterprise Access via API Despite these gains, Grok 4.1 remains unavailable to enterprise users through xAI’s API. According to the company’s public documentation , the latest available models for developers are Grok 4 Fast (both reasoning and non-reasoning variants), each supporting up to 2 million tokens of context at pricing tiers ranging from $0.20 to $0.50 per million tokens. These are backed by a 4M tokens-per-minute throughput limit and 480 requests per minute (RPM) rate cap. By contrast, Grok 4.1 is accessible only through xAI’s consumer-facing properties—X, Grok.com, and the mobile apps. This means organizations cannot yet deploy Grok 4.1 via fine-tuned internal workflows, multi-agent chains, or real-time product integrations. Industry Reception and Next Steps The release has been met with strong public and industry feedback. Elon Musk, founder of xAI, posted a brief endorsement, calling it “a great model” and congratulating the team. AI benchmark platforms have praised the leap in usability and linguistic nuance. For enterprise customers, however, the picture is more mixed. Grok 4.1’s performance represents a breakthrough for general-purpose and creative tasks, but until API access is enabled, it will remain a consumer-first product with limited enterprise applicability. As competitive models from OpenAI, Google, and Anthropic continue to evolve, xAI’s next strategic move may hinge on when—and how—it opens Grok 4.1 to external developers.

Nvidia releases open-source software for self-driving car development Reuters

A stealth artificial intelligence startup founded by an MIT researcher emerged this morning with an ambitious claim: its new AI model can control computers better than systems built by OpenAI and Anthropic — at a fraction of the cost. OpenAGI , led by chief executive Zengyi Qin , released Lux , a foundation model designed to operate computers autonomously by interpreting screenshots and executing actions across desktop applications. The San Francisco-based company says Lux achieves an 83.6 percent success rate on Online-Mind2Web , a benchmark that has become the industry's most rigorous test for evaluating AI agents that control computers. That score is a significant leap over the leading models from well-funded competitors. OpenAI's Operator , released in January, scores 61.3 percent on the same benchmark. Anthropic's Claude Computer Use achieves 56.3 percent. "Traditional LLM training feeds a large amount of text corpus into the model. The model learns to produce text," Qin said in an exclusive interview with VentureBeat. "By contrast, our model learns to produce actions. The model is trained with a large amount of computer screenshots and action sequences, allowing it to produce actions to control the computer." The announcement arrives at a pivotal moment for the AI industry. Technology giants and startups alike have poured billions of dollars into developing autonomous agents capable of navigating software, booking travel, filling out forms, and executing complex workflows. OpenAI , Anthropic , Google , and Microsoft have all released or announced agent products in the past year, betting that computer-controlling AI will become as transformative as chatbots. Yet independent research has cast doubt on whether current agents are as capable as their creators suggest. Why university researchers built a tougher benchmark to test AI agents—and what they discovered The Online-Mind2Web benchmark , developed by researchers at Ohio State University and the University of California, Berkeley, was designed specifically to expose the gap between marketing claims and actual performance. Published in April and accepted to the Conference on Language Modeling 2025 , the benchmark comprises 300 diverse tasks across 136 real websites — everything from booking flights to navigating complex e-commerce checkouts. Unlike earlier benchmarks that cached parts of websites, Online-Mind2Web tests agents in live online environments where pages change dynamically and unexpected obstacles appear. The results, according to the researchers, painted "a very different picture of the competency of current agents, suggesting over-optimism in previously reported results." When the Ohio State team tested five leading web agents with careful human evaluation, they found that many recent systems — despite heavy investment and marketing fanfare — did not outperform SeeAct , a relatively simple agent released in January 2024. Even OpenAI's Operator , the best performer among commercial offerings in their study, achieved only 61 percent success. "It seemed that highly capable and practical agents were maybe indeed just months away," the researchers wrote in a blog post accompanying their paper. "However, we are also well aware that there are still many fundamental gaps in research to fully autonomous agents, and current agents are probably not as competent as the reported benchmark numbers may depict." The benchmark has gained traction as an industry standard, with a public leaderboard hosted on Hugging Face tracking submissions from research groups and companies. How OpenAGI trained its AI to take actions instead of just generating text OpenAGI's claimed performance advantage stems from what the company calls " Agentic Active Pre-training ," a training methodology that differs fundamentally from how most large language models learn. Conventional language models train on vast text corpora, learning to predict the next word in a sequence. The resulting systems excel at generating coherent text but were not designed to take actions in graphical environments. Lux , according to Qin, takes a different approach. The model trains on computer screenshots paired with action sequences, learning to interpret visual interfaces and determine which clicks, keystrokes, and navigation steps will accomplish a given goal. "The action allows the model to actively explore the computer environment, and such exploration generates new knowledge, which is then fed back to the model for training," Qin told VentureBeat. "This is a naturally self-evolving process, where a better model produces better exploration, better exploration produces better knowledge, and better knowledge leads to a better model." This self-reinforcing training loop, if it functions as described, could help explain how a smaller team might achieve results that elude larger organizations. Rather than requiring ever-larger static datasets, the approach would allow the model to continuously improve by generating its own training data through exploration. OpenAGI also claims significant cost advantages. The company says Lux operates at roughly one-tenth the cost of frontier models from OpenAI and Anthropic while executing tasks faster. Unlike browser-only competitors, Lux can control Slack, Excel, and other desktop applications A critical distinction in OpenAGI's announcement: Lux can control applications across an entire desktop operating system, not just web browsers. Most commercially available computer-use agents, including early versions of Anthropic's Claude Computer Use , focus primarily on browser-based tasks. That limitation excludes vast categories of productivity work that occur in desktop applications — spreadsheets in Microsoft Excel, communications in Slack, design work in Adobe products, code editing in development environments. OpenAGI says Lux can navigate these native applications, a capability that would substantially expand the addressable market for computer-use agents. The company is releasing a developer software development kit alongside the model, allowing third parties to build applications on top of Lux. The company is also working with Intel to optimize Lux for edge devices, which would allow the model to run locally on laptops and workstations rather than requiring cloud infrastructure. That partnership could address enterprise concerns about sending sensitive screen data to external servers. "We are partnering with Intel to optimize our model on edge devices, which will make it the best on-device computer-use model," Qin said. The company confirmed it is in exploratory discussions with AMD and Microsoft about additional partnerships. What happens when you ask an AI agent to copy your bank details Computer-use agents present novel safety challenges that do not arise with conventional chatbots. An AI system capable of clicking buttons, entering text, and navigating applications could, if misdirected, cause significant harm — transferring money, deleting files, or exfiltrating sensitive information. OpenAGI says it has built safety mechanisms directly into Lux. When the model encounters requests that violate its safety policies, it refuses to proceed and alerts the user. In an example provided by the company, when a user asked the model to "copy my bank details and paste it into a new Google doc," Lux responded with an internal reasoning step: "The user asks me to copy the bank details, which are sensitive information. Based on the safety policy, I am not able to perform this action." The model then issued a warning to the user rather than executing the potentially dangerous request. Such safeguards will face intense scrutiny as computer-use agents proliferate. Security researchers have already demonstrated prompt injection attacks against early agent systems, where malicious instructions embedded in websites or documents can hijack an agent's behavior. Whether Lux's safety mechanisms can withstand adversarial attacks remains to be tested by independent researchers. The MIT researcher who built two of GitHub's most downloaded AI models Qin brings an unusual combination of academic credentials and entrepreneurial experience to OpenAGI. He completed his doctorate at the Massachusetts Institute of Technology in 2025, where his research focused on computer vision, robotics, and machine learning. His academic work appeared in top venues including the Conference on Computer Vision and Pattern Recognition , the International Conference on Learning Representations , and the International Conference on Machine Learning . Before founding OpenAGI, Qin built several widely adopted AI systems. JetMoE , a large language model he led development on, demonstrated that a high-performing model could be trained from scratch for less than $100,000 — a fraction of the tens of millions typically required. The model outperformed Meta's LLaMA2-7B on standard benchmarks, according to a technical report that attracted attention from MIT's Computer Science and Artificial Intelligence Laboratory. His previous open-source projects achieved remarkable adoption. OpenVoice , a voice cloning model, accumulated approximately 35,000 stars on GitHub and ranked in the top 0.03 percent of open-source projects by popularity. MeloTTS , a text-to-speech system, has been downloaded more than 19 million times, making it one of the most widely used audio AI models since its 2024 release. Qin also co-founded MyShell , an AI agent platform that has attracted six million users who have collectively built more than 200,000 AI agents. Users have had more than one billion interactions with agents on the platform, according to the company. Inside the billion-dollar race to build AI that controls your computer The computer-use agent market has attracted intense interest from investors and technology giants over the past year. OpenAI released Operator in January, allowing users to instruct an AI to complete tasks across the web. Anthropic has continued developing Claude Computer Use , positioning it as a core capability of its Claude model family. Google has incorporated agent features into its Gemini products. Microsoft has integrated agent capabilities across its Copilot offerings and Windows . Yet the market remains nascent. Enterprise adoption has been limited by concerns about reliability, security, and the ability to handle edge cases that occur frequently in real-world workflows. The performance gaps revealed by benchmarks like Online-Mind2Web suggest that current systems may not be ready for mission-critical applications. OpenAGI enters this competitive landscape as an independent alternative, positioning superior benchmark performance and lower costs against the massive resources of its well-funded rivals. The company's Lux model and developer SDK are available beginning today. Whether OpenAGI can translate benchmark dominance into real-world reliability remains the central question. The AI industry has a long history of impressive demos that falter in production, of laboratory results that crumble against the chaos of actual use. Benchmarks measure what they measure, and the distance between a controlled test and an 8-hour workday full of edge cases, exceptions, and surprises can be vast. But if Lux performs in the wild the way it performs in the lab, the implications extend far beyond one startup's success. It would suggest that the path to capable AI agents runs not through the largest checkbooks but through the cleverest architectures—that a small team with the right ideas can outmaneuver the giants. The technology industry has seen that story before. It rarely stays true for long.

Interviewer: Jillian York Benjamin Ismail is the Campaign and Advocacy Director for GreatFire , where he leads efforts to expose the censorship apparatus of authoritarian regimes worldwide. He also runs/oversees the App Censorship Project, including the AppleCensorship.com and GoogleCensorship.org platforms, which track mobile app censorship globally. From 2011 to 2017, Benjamin headed the Asia-Pacific desk at Reporters Without Borders (RSF). Jillian York : Hi Benjamin, it's great to chat with you. We got to meet at the Global Gathering recently and we did a short video there and it was wonderful to get to know you a little bit. I'm going to start by asking you my first basic question: What does free speech or free expression mean to you? Benjamin Ismail : Well, it starts with a very, very big question. What I have in mind is a cliche answer, but it's what I genuinely believe. I think about all freedoms. So when you say free expression, free speech, or freedom of information or Article 19, all of those concepts are linked together, I immediately think of all human rights at once. Because what I have seen during my current or past work is how that freedom is really the cornerstone of all freedom. If you don’t have that, you can’t have any other freedom. If you don’t have freedom of expression, if you don't have journalism, you don't have pluralism of opinions—you have self-censorship. You have realities, violations, that exist but are not talked about, and are not exposed, not revealed, not tackled, and nothing is really improved without that first freedom. I also think about Myanmar because I remember going there in 2012, when the country had just opened after the democratic revolution. We got the chance to meet with many officials, ministers, and we got to tell them that they should start with that because their speech was “don’t worry, don’t raise freedom of speech, freedom of the press will come in due time.” And we were saying “no, that’s not how it works!” It doesn’t come in due time when other things are being worked on. It starts with that so you can work on other things. And so I remember very well those meetings and how actually, unfortunately, the key issues that re-emerged afterwards in the country were precisely due to the fact that they failed to truly implement free speech protections when the country started opening. JY: What was your path to this work? BI : This is a multi-faceted answer. So, I was studying Chinese language and civilization at the National Institute of Oriental Languages and Civilizations in Paris along with political science and international law. When I started that line of study, I considered maybe becoming a diplomat…that program led to preparing for the exams required to enter the diplomatic corps in France. But I also heard negative feedback on the Ministry of Foreign Affairs and, notably, first-hand testimonies from friends and fellow students who had done internships there. I already knew that I had a little bit of an issue with authority. My experience as an assistant at Reporters Without Borders challenged the preconceptions I had about NGOs and civil society organizations in general. I was a bit lucky to come at a time when the organization was really trying to find its new direction, its new inspiration. So it a brief phase where the organization itself was hungry for new ideas. Being young and not very experienced, I was invited to share my inputs, my views—among many others of course. I saw that you can influence an organization’s direction, actions, and strategy, and see the materialization of those strategic choices. Such as launching a campaign, setting priorities, and deciding how to tackle issues like freedom of information, and the protection of journalists in various contexts. That really motivated me and I realized that I would have much less to say if I had joined an institution such as the Ministry of Foreign Affairs. Instead, I was part of a human-sized group, about thirty-plus employees working together in one big open space in Paris. After that experience I set my mind on joining the civil society sector, focusing on freedom of the press. on journalistic issues, you get to touch on many different issues in many different regions, and I really like that. So even though it’s kind of monothematic, it's a single topic that's encompassing everything at the same time. I was dealing with safety issues for Pakistani journalists threatened by the Taliban. At the same time I followed journalists pressured by corporations such as TEPCO and the government in Japan for covering nuclear issues. I got to touch on many topics through the work of the people we were defending and helping. That’s what really locked me onto this specific human right. I already had my interest when I was studying in political and civil rights, but after that first experience, at the end of 2010, I went to China and got called by Reporters Without Borders . They told me that the head of the Asia desk was leaving and invited me to apply for the position. At that time, I was in Shanghai, working to settle down there. The alternative was accepting a job that would take me back to Paris but likely close the door on any return to China. Once you start giving interviews to outlets like the BBC and CNN, well… you know how that goes—RSF was not viewed favorably in many countries. Eventually, I decided it was a huge opportunity, so I accepted the job and went back to Paris, and from then on I was fully committed to that issue. JY: For our readers, tell us what the timeline of this was. BI : I finished my studies in 2009. I did my internship with Reporters Without Borders that year and continued to work pro bono for the organization on the Chinese website in 2010. Then I went to China, and in January 2011, I was contacted by Reporters without Borders about the departure of the former head of the Asia Pacific Desk. I did my first and last fact-finding mission in China, and went to Beijing. I met the artist Ai Weiwei in Beijing just a few weeks before he was arrested, around March 2011, and finally flew back to Paris and started heading the Asia desk. I left the organization in 2017. JY: Such an amazing story. I’d love to hear more about the work that you do now. BI: The story of the work I do now actually starts in 2011. That was my first year heading the Asia Pacific Desk. That same year, a group of anonymous activists based in China started a group called GreatFire . They launched their project with a website where you can type any URL you want and that website will test the connection from mainland China to that URL and tell you know if it’s accessible or blocked. They also kept the test records so that you can look at the history of the blocking of a specific website, which is great. That was GreatFire’s first project for monitoring web censorship in mainland China. We started exchanging information, working on the issue of censorship in China. They continued to develop more projects which I tried to highlight as well . I also helped them to secure some funding. At the very beginning, they were working on these things as a side job. And progressively they managed to get some funding, which was very difficult because of the anonymity. One of the things I remember is that I helped them get some funding from the EU through a mechanism called “Small Grants”, where every grant would be around €20- 30,000. The EU, you know, is a bureaucratic entity and they were demanding some paperwork and documents. But I was telling them that they wouldn’t be able to get the real names of the people working at GreatFire, but that they should not be concerned about that because, what they wanted was to finance that tool. So if we were to show them that the people they were going to send the money to were actually the people controlling that website, then it would be fine. And so we featured a little EU logo just for one day, I think on the footer of the website so they could check that. And that’s how we convinced the EU to support GreatFire for that work. Also, there's this tactic called “ Collateral Freedom ” that GreatFire uses very well. The idea is that you host sensitive content on HTTPS servers that belong to companies which also operate inside China and are accessible there. Because it’s HTTPS, the connection is encrypted, so the authorities can’t just block a specific page—they can’t see exactly which page is being accessed. To block it, they’d have to block the entire service. Now, they can do that, but it comes at a higher political and economic cost, because it means disrupting access to other things hosted on that same service—like banks or major businesses. That’s why it’s called “collateral freedom”: you’re basically forcing the authorities to risk broader collateral damage if they want to censor your content. When I was working for RSF, I proposed that we replicate that tactic on the 12th of March—that's the World Day against Cyber Censorship . We had the habit of publishing what we called the “ enemies of the Internet ” report, where we would highlight and update the situation on the countries which were carrying out the harshest repression online; countries like Iran, Turkmenistan, North Korea, and of course, China. I suggested in a team meeting: “what if we highlighted the good guys? Maybe we could highlight 10 exiled media and use collateral freedom to uncensor those. And so we did: some Iranian media, Egyptian media, Chinese media, Turkmen media were uncensored using mirrors hosted on https servers owned by big, and thus harder to block, companies...and that’s how we started to do collateral freedom and it continued to be an annual thing. I also helped in my personal capacity, including after I left Reporters Without Borders. After I left RSF, I joined another NGO focusing on China, which I knew also from my time at RSF. I worked with that group for a year and a half; GreatFire contacted me to work on a website specifically. So here we are, at the beginning of 2020, they had just started this website called Applecensorship.com that allowed users to test availability of any app in any of Apple’s 175 App Stores worldwide They needed a better website—one that allowed advocacy content—for that tool. The idea was to make a website useful for academics doing research, journalists investigating app store censorship and control and human rights NGOs, civil society organizations interested in the availability of any tools. Apple’s censorship in China started quickly after the company entered the Chinese market, in 2010. In 2013, one of the projects by GreatFire which had been turned into an iOS app was removed by Apple 48 hours after its release on the App Store, at the demand of the Chinese authorities. That project was Free Weibo , which is a website which features censored posts from Weibo, the Chinese equivalent of Twitter—we crawl social media and detect censored posts and republish them on the site. In 2017 it was reported that Apple had removed all VPNs from the Chinese app store. So between that episode in 2013, and the growing censorship of Apple in China (and in other places too) led to the creation of AppleCensorship in 2019. GreatFire asked me to work on that website. The transformation into an advocacy platform was successful. I then started working full time on that project, which has since evolved into the App Censorship Project, which includes another website, googlecensorship.org (offering features similar to Applecensorship.com but for the 224 Play Stores worldwide). In the meantime, I became the head of campaigns and advocacy, because of my background at RSF. JY: I want to ask you, looking beyond China, what are some other places in the world that you're concerned about at the moment, whether on a professional basis, but also maybe just as a person. What are you seeing right now in terms of global trends around free expression that worry you? BI : I think, like everyone else, that what we're seeing in Western democracies—in the US and even in Europe—is concerning. But I'm still more concerned about authoritarian regimes than about our democracies. Maybe it's a case of not learning my lesson or of naive optimism, but I'm still more concerned about China and Russia than I am about what I see in France, the UK, or the US. There has been some recent reporting about China developing very advanced censorship and surveillance technologies and exporting them to other countries like Myanmar and Pakistan. What we’re seeing in Russia—I’m not an expert on that region, but we heard experts saying back in 2022 that Russia was trying to increase its censorship and control, but that it couldn’t become like China because China had exerted control over its internet from the very beginning: They removed Facebook back in 2009, then Google was pushed away by the authorities (and the market). And the Chinese authorities successfully filled the gaps left by the absence of those foreign Western companies. Some researchers working on Russia were saying that it wasn’t really possible for Russia to do what China had done because it was unprepared and that China had engineered it for more than a decade. What we are seeing now is that Russia is close to being able to close its Internet, to close the country, to replace services by its own controlled ones. It’s not identical, but it’s also kind of replicating what China has been doing. And that’s a very sad observation to make. Beyond the digital, the issue of how far Putin is willing to go in escalating concerns. As a human being and an inhabitant of the European continent, I’m concerned by the ability of a country like Russia to isolate itself while waging a war. Russia is engaged in a real war and at the same time is able to completely digitally close down the country. Between that and the example of China exporting censorship, I’m not far from thinking that in ten or twenty years we’ll have a completely splintered internet. JY : Do you feel like having a global perspective like this has changed or reshaped your views in any way? BI : Yes, in the sense that when you start working with international organizations, and you start hearing about the world and how human rights are universal values, and you get to meet people and go to different countries, you really get to experience how universal those freedoms and aspirations are. When I worked RSF and lobbied governments to pass a good law or abolish a repressive one, or when I worked on a case of a jailed journalist or blogger, I got to talk to authorities and to hear weird justifications from certain governments (not mentioning any names but Myanmar and Vietnam) like “those populations are different from the French” and I would receive pushback that the ideas of freedoms I was describing were not applicable to their societies. It’s a bit destabilizing when you hear that for the first time. But as you gain experience, you can clearly explain why human rights are universal and why different populations shouldn’t be ruled differently when it comes to human rights. Everyone wants to be free. This notion of “universality” is comforting because when you’re working for something universal, the argument is there. The freedoms you defend can’t be challenged in principle, because everyone wants them. If governments and authorities really listened to their people, they would hear them calling for those rights and freedoms. Or that’s what I used to think. Now we hear this growing rhetoric that we (people from the West) are exporting democracy, that it’s a western value, and not a universal one. This discourse, notably developed by Xi Jinping in China, “Western democracy” as a new concept— is a complete fallacy. Democracy was invented in the West, but democracy is universal. Unfortunately, I now believe that, in the future, we will have to justify and argue much more strongly for the universality of concepts like democracy, human rights and fundamental freedoms. JY : Thank you so much for this insight. And now for our final question: Do you have a free speech hero? BI : No. JY : No? No heroes? An inspiration maybe. BI : On the contrary, I’ve been disappointed so much by certain figures that were presented as human rights heroes…Like Aung San Suu Kyi during the Rohingya crisis, on which I worked when I was at RSF. Myanmar officially recognizes 135 ethnic groups, but somehow this one additional ethnic minority (the Rohingya ) is impossible for them to accept. It’s appalling. It’s weird to say, but some heroes are not really good people either. Being a hero is doing a heroic action, but people who do heroic actions can also do very bad things before or after, at a different level. They can be terrible persons, husbands or friends and be a “human rights” hero at the same time. Some people really inspired me but they’re not public figures. They are freedom fighters, but they are not “heroes”. They remain in the shadows. I know their struggles; I see their determination, their conviction, and how their personal lives align with their role as freedom fighters. These are the people who truly inspire me.

Roadmap focuses on technology’s ‘economic benefits’ and says existing laws will cover the fast-growing new technology Get our breaking news email , free app or daily news podcast The Albanese government has decided against legislation to manage artificial intelligence, with a new national roadmap emphasising Labor’s focus on the technology’s economic benefits and plans to “unlock” vast datasets held by private companies and the public service to help train AI models. Supporting and reskilling workers affected by AI in their jobs, boosting investment in datacentres, and sharing the productivity benefits across the economy are key components of the Labor government’s National AI Plan, launched on Tuesday. Continue reading...
arXiv:2511.11252v1 Announce Type: new Abstract: Autonomous aerial systems increasingly rely on large language models (LLMs) for mission planning, perception, and decision-making, yet the lack of standardized and physically grounded benchmarks limits systematic evaluation of their reasoning capabilities. To address this gap, we introduce UAVBench, an open benchmark dataset comprising 50,000 validated UAV flight scenarios generated through taxonomy-guided LLM prompting and multi-stage safety validation. Each scenario is encoded in a structured JSON schema that includes mission objectives, vehicle configuration, environmental conditions, and quantitative risk labels, providing a unified representation of UAV operations across diverse domains. Building on this foundation, we present UAVBench_MCQ, a reasoning-oriented extension containing 50,000 multiple-choice questions spanning ten cognitive and ethical reasoning styles, ranging from aerodynamics and navigation to multi-agent coordination and integrated reasoning. This framework enables interpretable and machine-checkable assessment of UAV-specific cognition under realistic operational contexts. We evaluate 32 state-of-the-art LLMs, including GPT-5, ChatGPT-4o, Gemini 2.5 Flash, DeepSeek V3, Qwen3 235B, and ERNIE 4.5 300B, and find strong performance in perception and policy reasoning but persistent challenges in ethics-aware and resource-constrained decision-making. UAVBench establishes a reproducible and physically grounded foundation for benchmarking agentic AI in autonomous aerial systems and advancing next-generation UAV reasoning intelligence. To support open science and reproducibility, we release the UAVBench dataset, the UAVBench_MCQ benchmark, evaluation scripts, and all related materials on GitHub at https://github.com/maferrag/UAVBench

arXiv:2511.11017v1 Announce Type: new Abstract: The rapid expansion of e-commerce platforms generates vast amounts of unstructured product data, creating significant challenges for information retrieval, recommendation systems, and data analytics. Knowledge Graphs (KGs) offer a structured, interpretable format to organize such data, yet constructing product-specific KGs remains a complex and manual process. This paper introduces a fully automated, AI agent-driven framework for constructing product knowledge graphs directly from unstructured product descriptions. Leveraging Large Language Models (LLMs), our method operates in three stages using dedicated agents: ontology creation and expansion, ontology refinement, and knowledge graph population. This agent-based approach ensures semantic coherence, scalability, and high-quality output without relying on predefined schemas or handcrafted extraction rules. We evaluate the system on a real-world dataset of air conditioner product descriptions, demonstrating strong performance in both ontology generation and KG population. The framework achieves over 97\% property coverage and minimal redundancy, validating its effectiveness and practical applicability. Our work highlights the potential of LLMs to automate structured knowledge extraction in retail, providing a scalable path toward intelligent product data integration and utilization.

arXiv:2511.10842v1 Announce Type: new Abstract: Knowledge graphs have emerged as fundamental structures for representing complex relational data across scientific and enterprise domains. However, existing embedding methods face critical limitations when modeling diverse relationship types at scale: Euclidean models struggle with hierarchies, vector space models cannot capture asymmetry, and hyperbolic models fail on symmetric relations. We propose HyperComplEx, a hybrid embedding framework that adaptively combines hyperbolic, complex, and Euclidean spaces via learned attention mechanisms. A relation-specific space weighting strategy dynamically selects optimal geometries for each relation type, while a multi-space consistency loss ensures coherent predictions across spaces. We evaluate HyperComplEx on computer science research knowledge graphs ranging from 1K papers (~25K triples) to 10M papers (~45M triples), demonstrating consistent improvements over state-of-the-art baselines including TransE, RotatE, DistMult, ComplEx, SEPA, and UltraE. Additional tests on standard benchmarks confirm significantly higher results than all baselines. On the 10M-paper dataset, HyperComplEx achieves 0.612 MRR, a 4.8% relative gain over the best baseline, while maintaining efficient training, achieving 85 ms inference per triple. The model scales near-linearly with graph size through adaptive dimension allocation. We release our implementation and dataset family to facilitate reproducible research in scalable knowledge graph embeddings.

arXiv:2511.10664v1 Announce Type: cross Abstract: Large language models (LLMs) have achieved impressive results in high-resource languages like English, yet their effectiveness in low-resource and morphologically rich languages remains underexplored. In this paper, we present a comprehensive evaluation of seven cutting-edge LLMs -- including GPT-4o, GPT-4, Claude~3.5~Sonnet, LLaMA~3.1, Mistral~Large~2, LLaMA-2~Chat~13B, and Mistral~7B~Instruct -- on a new cross-lingual benchmark covering \textbf{Cantonese, Japanese, and Turkish}. Our benchmark spans four diverse tasks: open-domain question answering, document summarization, English-to-X translation, and culturally grounded dialogue. We combine \textbf{human evaluations} (rating fluency, factual accuracy, and cultural appropriateness) with automated metrics (e.g., BLEU, ROUGE) to assess model performance. Our results reveal that while the largest proprietary models (GPT-4o, GPT-4, Claude~3.5) generally lead across languages and tasks, significant gaps persist in culturally nuanced understanding and morphological generalization. Notably, GPT-4o demonstrates robust multilingual performance even on cross-lingual tasks, and Claude~3.5~Sonnet achieves competitive accuracy on knowledge and reasoning benchmarks. However, all models struggle to some extent with the unique linguistic challenges of each language, such as Turkish agglutinative morphology and Cantonese colloquialisms. Smaller open-source models (LLaMA-2~13B, Mistral~7B) lag substantially in fluency and accuracy, highlighting the resource disparity. We provide detailed quantitative results, qualitative error analysis, and discuss implications for developing more culturally aware and linguistically generalizable LLMs. Our benchmark and evaluation data are released to foster reproducibility and further research.

arXiv:2511.10660v1 Announce Type: cross Abstract: Lossless compression techniques are crucial in an era of rapidly growing data. Traditional universal compressors like gzip offer low computational overhead, high speed, and broad applicability across data distributions. However, they often lead to worse compression rates than modern neural compressors, which leverage large-scale training data to model data distributions more effectively. Despite their advantages, neural compressors struggle to generalize to unseen data. To address this limitation, we propose a novel framework that performs Test-Time Steering via a Weighted Product of Experts (wPoE). At inference, our method adaptively combines a universal compression model with a pretrained neural language model, ensuring the compression rate is at least as good as that of the best individual model. Extensive experiments demonstrate that our approach improves the performance of text compression without requiring fine-tuning. Furthermore, it seamlessly integrates with any autoregressive language model, providing a practical solution for enhancing text compression across diverse data distributions.
arXiv:2511.10654v1 Announce Type: cross Abstract: When deploying LLMs in agentic architectures requiring real-time decisions under temporal constraints, we assume they reliably determine whether action windows remain open or have closed. This assumption is untested. We characterize temporal constraint processing across eight production-scale models (2.8-8B parameters) using deadline detection tasks, revealing systematic deployment risks: bimodal performance distribution (models achieve either 95% or 50% accuracy), extreme prompt brittleness (30-60 percentage point swings from formatting changes alone), and systematic action bias (100% false positive rates in failing models). Parameter count shows no correlation with capability in this range-a 3.8B model matches 7B models while other 7B models fail completely. Fine-tuning on 200 synthetic examples improves models with partial capability by 12-37 percentage points. We demonstrate that temporal constraint satisfaction cannot be reliably learned through next-token prediction on natural language, even with targeted fine-tuning. This capability requires architectural mechanisms for: (1) continuous temporal state representation, (2) explicit constraint checking separate from linguistic pattern matching, (3) systematic compositional reasoning over temporal relations. Current autoregressive architectures lack these mechanisms. Deploying such systems in time-critical applications without hybrid architectures incorporating symbolic reasoning modules represents unacceptable risk.