Fresh from the feed
Filter by timeframe and category to zero in on the moves that matter.

arXiv:2511.12785v1 Announce Type: new Abstract: Color harmonization adjusts the colors of an inserted object so that it perceptually matches the surrounding image, resulting in a seamless composite. The harmonization problem naturally arises in augmented reality (AR), yet harmonization algorithms are not currently integrated into AR pipelines because real-time solutions are scarce. In this work, we address color harmonization for AR by proposing a lightweight approach that supports on-device inference. For this, we leverage classical optimal transport theory by training a compact encoder to predict the Monge-Kantorovich transport map. We benchmark our MKL-Harmonizer algorithm against state-of-the-art methods and demonstrate that for real composite AR images our method achieves the best aggregated score. We release our dedicated AR dataset of composite images with pixel-accurate masks and data-gathering toolkit to support further data acquisition by researchers.

arXiv:2511.12801v1 Announce Type: new Abstract: Accurate segmentation of brain tumors is vital for diagnosis, surgical planning, and treatment monitoring. Deep learning has advanced on benchmarks, but two issues limit clinical use: no uncertainty estimates for errors and no segmentation of healthy brain structures around tumors for surgery. Current methods fail to unify tumor localization with anatomical context and lack confidence scores. This study presents an uncertainty-aware framework augmenting nnUNet with a channel for voxel-wise uncertainty. Trained on BraTS2023, it yields a correlation of 0.750 and RMSD of 0.047 for uncertainty without hurting tumor accuracy. It predicts uncertainty in one pass, with no extra networks or inferences, aiding clinical decisions. For whole-brain context, a unified model combines normal and cancer datasets, achieving a DSC of 0.81 for brain structures and 0.86 for tumor, with robust key-region performance. Combining both innovations gives the first model outputting tumor in natural surroundings plus an overlaid uncertainty map. Visual checks of outputs show uncertainty offers key insights to evaluate predictions and fix errors, helping informed surgical decisions from AI.

arXiv:2511.12810v1 Announce Type: new Abstract: Camouflaged object detection is an emerging and challenging computer vision task that requires identifying and segmenting objects that blend seamlessly into their environments due to high similarity in color, texture, and size. This task is further complicated by low-light conditions, partial occlusion, small object size, intricate background patterns, and multiple objects. While many sophisticated methods have been proposed for this task, current methods still struggle to precisely detect camouflaged objects in complex scenarios, especially with small and multiple objects, indicating room for improvement. We propose a Multi-Scale Recursive Network that extracts multi-scale features via a Pyramid Vision Transformer backbone and combines them via specialized Attention-Based Scale Integration Units, enabling selective feature merging. For more precise object detection, our decoder recursively refines features by incorporating Multi-Granularity Fusion Units. A novel recursive-feedback decoding strategy is developed to enhance global context understanding, helping the model overcome the challenges in this task. By jointly leveraging multi-scale learning and recursive feature optimization, our proposed method achieves performance gains, successfully detecting small and multiple camouflaged objects. Our model achieves state-of-the-art results on two benchmark datasets for camouflaged object detection and ranks second on the remaining two. Our codes, model weights, and results are available at \href{https://github.com/linaagh98/MSRNet}{https://github.com/linaagh98/MSRNet}.

arXiv:2511.12834v1 Announce Type: new Abstract: The proliferation of generative AI has led to hyper-realistic synthetic videos, escalating misuse risks and outstripping binary real/fake detectors. We introduce SAGA (Source Attribution of Generative AI videos), the first comprehensive framework to address the urgent need for AI-generated video source attribution at a large scale. Unlike traditional detection, SAGA identifies the specific generative model used. It uniquely provides multi-granular attribution across five levels: authenticity, generation task (e.g., T2V/I2V), model version, development team, and the precise generator, offering far richer forensic insights. Our novel video transformer architecture, leveraging features from a robust vision foundation model, effectively captures spatio-temporal artifacts. Critically, we introduce a data-efficient pretrain-and-attribute strategy, enabling SAGA to achieve state-of-the-art attribution using only 0.5\% of source-labeled data per class, matching fully supervised performance. Furthermore, we propose Temporal Attention Signatures (T-Sigs), a novel interpretability method that visualizes learned temporal differences, offering the first explanation for why different video generators are distinguishable. Extensive experiments on public datasets, including cross-domain scenarios, demonstrate that SAGA sets a new benchmark for synthetic video provenance, providing crucial, interpretable insights for forensic and regulatory applications.

arXiv:2511.12868v1 Announce Type: new Abstract: Multimodal large language models (LLMs) have made rapid progress in visual understanding, yet their extension from images to videos often reduces to a naive concatenation of frame tokens. In this work, we investigate what video finetuning brings to multimodal LLMs. We propose Visual Chain-of-Thought (vCoT), an explicit reasoning process that generates transitional event descriptions between consecutive frames. Using vCoT, we systematically compare image-only LVLMs with their video-finetuned counterparts, both with and without access to these transitional cues. Our experiments show that vCoT significantly improves the performance of image-only models on long-form video question answering, while yielding only marginal gains for video-finetuned models. This suggests that the latter already capture frame-to-frame transitions implicitly. Moreover, we find that video models transfer this temporal reasoning ability to purely static settings, outperforming image models' baselines on relational visual reasoning tasks.
arXiv:2511.12870v1 Announce Type: new Abstract: The widespread use of multi-sensor systems has increased research in multi-view action recognition. While existing approaches in multi-view setups with fully overlapping sensors benefit from consistent view coverage, partially overlapping settings where actions are visible in only a subset of views remain underexplored. This challenge becomes more severe in real-world scenarios, as many systems provide only limited input modalities and rely on sequence-level annotations instead of dense frame-level labels. In this study, we propose View-aware Cross-modal Knowledge Distillation (ViCoKD), a framework that distills knowledge from a fully supervised multi-modal teacher to a modality- and annotation-limited student. ViCoKD employs a cross-modal adapter with cross-modal attention, allowing the student to exploit multi-modal correlations while operating with incomplete modalities. Moreover, we propose a View-aware Consistency module to address view misalignment, where the same action may appear differently or only partially across viewpoints. It enforces prediction alignment when the action is co-visible across views, guided by human-detection masks and confidence-weighted Jensen-Shannon divergence between their predicted class distributions. Experiments on the real-world MultiSensor-Home dataset show that ViCoKD consistently outperforms competitive distillation methods across multiple backbones and environments, delivering significant gains and surpassing the teacher model under limited conditions.

arXiv:2511.13655v1 Announce Type: new Abstract: Earth observation data presents a unique challenge: it is spatial like images, sequential like video or text, and highly multimodal. We present OlmoEarth: a multimodal, spatio-temporal foundation model that employs a novel self-supervised learning formulation, masking strategy, and loss all designed for the Earth observation domain. OlmoEarth achieves state-of-the-art performance compared to 12 other foundation models across a variety of research benchmarks and real-world tasks from external partners. When evaluating embeddings OlmoEarth achieves the best performance on 15 out of 24 tasks, and with full fine-tuning it is the best on 19 of 29 tasks. We deploy OlmoEarth as the backbone of an end-to-end platform for data collection, labeling, training, and inference of Earth observation models. The OlmoEarth Platform puts frontier foundation models and powerful data management tools into the hands of non-profits and NGOs working to solve the world's biggest problems. OlmoEarth source code, training data, and pre-trained weights are available at $\href{https://github.com/allenai/olmoearth_pretrain}{\text{https://github.com/allenai/olmoearth_pretrain}}$.

arXiv:2510.17114v2 Announce Type: replace Abstract: This paper introduces a method for using LED-based environmental lighting to produce visually imperceptible watermarks for consumer cameras. Our approach optimizes an LED light source's spectral profile to be minimally visible to the human eye while remaining highly detectable by typical consumer cameras. The method jointly considers the human visual system's sensitivity to visible spectra, modern consumer camera sensors' spectral sensitivity, and narrowband LEDs' ability to generate broadband spectra perceived as "white light" (specifically, D65 illumination). To ensure imperceptibility, we employ spectral modulation rather than intensity modulation. Unlike conventional visible light communication, our approach enables watermark extraction at standard low frame rates (30-60 fps). While the information transfer rate is modest-embedding 128 bits within a 10-second video clip-this capacity is sufficient for essential metadata supporting privacy protection and content verification.

arXiv:2511.11830v1 Announce Type: cross Abstract: We consider a discrete-time formulation for a class of high-dimensional stochastic joint replenishment problems. First, we approximate the problem by a continuous-time impulse control problem. Exploiting connections among the impulse control problem, backward stochastic differential equations (BSDEs) with jumps, and the stochastic target problem, we develop a novel, simulation-based computational method that relies on deep neural networks to solve the impulse control problem. Based on that solution, we propose an implementable inventory control policy for the original (discrete-time) stochastic joint replenishment problem, and test it against the best available benchmarks in a series of test problems. For the problems studied thus far, our method matches or beats the best benchmark we could find, and it is computationally feasible up to at least 50 dimensions -- that is, 50 stock-keeping units (SKUs).

Google on Monday released security updates for its Chrome browser to address two security flaws, including one that has come under active exploitation in the wild. The vulnerability in question is CVE-2025-13223 (CVSS score: 8.8), a type confusion vulnerability in the V8 JavaScript and WebAssembly engine that could be exploited to achieve arbitrary code execution or program crashes. "Type
Databricks in talks to raise capital at above $130 billion valuation, The Information reports Reuters
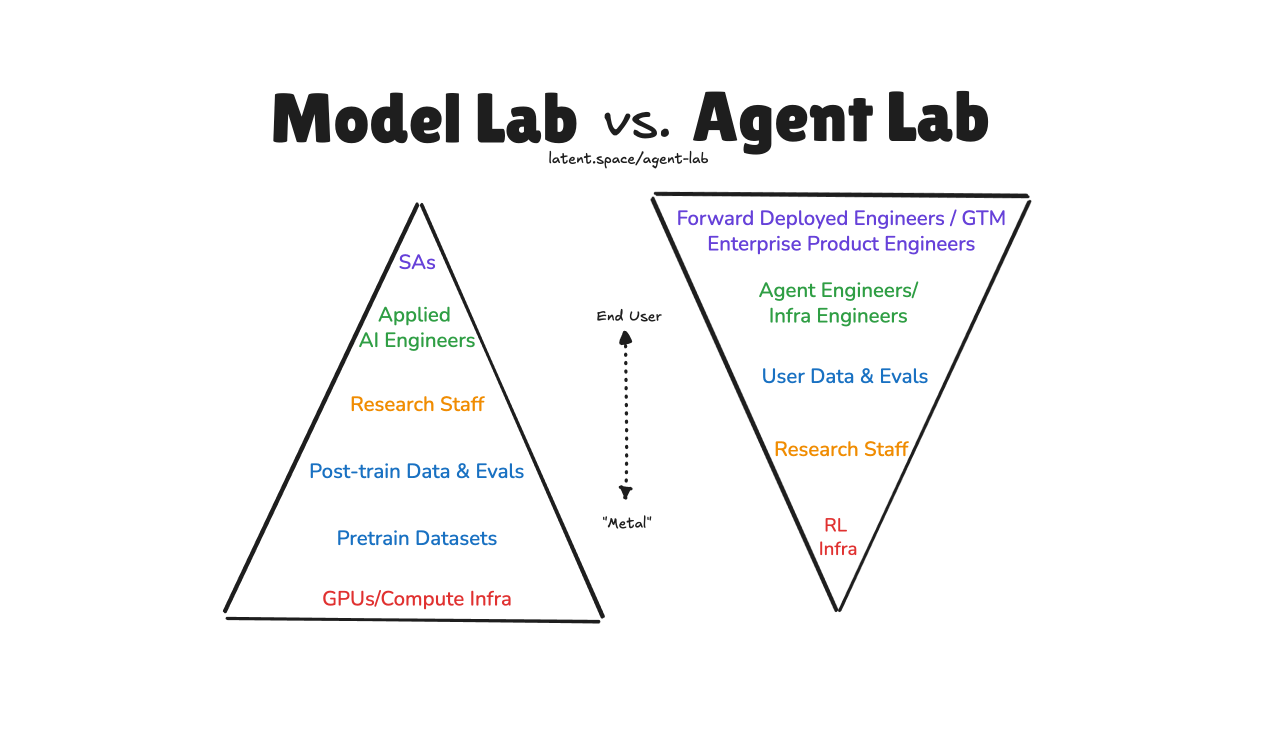
How great Agent Engineering and Research are combining in a new playbook for building high growth AI startups that doesn't involve training a SOTA LLM.

(c) SANS Internet Storm Center. https://isc.sans.edu Creative Commons Attribution-Noncommercial 3.0 United States License.
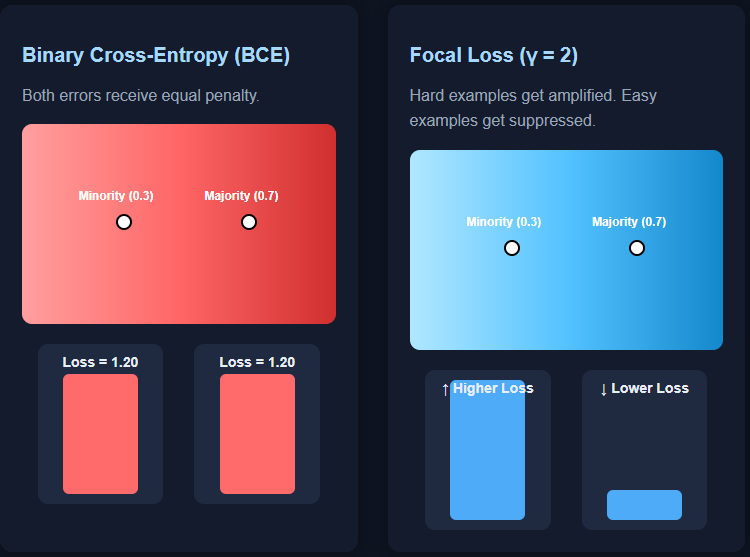
Binary cross-entropy (BCE) is the default loss function for binary classification—but it breaks down badly on imbalanced datasets. The reason is subtle but important: BCE weighs mistakes from both classes equally, even when one class is extremely rare. Imagine two predictions: a minority-class sample with true label 1 predicted at 0.3, and a majority-class sample […] The post Focal Loss vs Binary Cross-Entropy: A Practical Guide for Imbalanced Classification appeared first on MarkTechPost .

Ockham Book Awards dropped two titles from contention after new guidelines introduced on artificial intelligence use The books of two award-winning New Zealand authors have been disqualified from consideration for the country’s top literature prize because artificial intelligence was used in the creation of their cover designs. Stephanie Johnson’s collection of short stories Obligate Carnivore and Elizabeth Smither’s collection of novellas Angel Train were submitted to the 2026 Ockham book awards’ NZ$65,000 fiction prize in October, but were ruled out of the competition the following month in light of new guidelines around AI use . Continue reading...
Guidance for setting up comprehensive AI evaluation processes.

Microsoft has released an emergency Windows 10 KB5072653 out-of-band update to resolve ongoing issues with installing the November extended security updates. [...]
Seven packages published on the Node Package Manager (npm) registry use the Adspect cloud-based service to separate researchers from potential victims and lead them to malicious locations. [...]
Jeff Bezos Brings Signature Management Style to $6 Billion AI Startup Bloomberg.com

It's a "violation of foundational ethical principles of human participant research."