Fresh from the feed
Filter by timeframe and category to zero in on the moves that matter.
Introduction
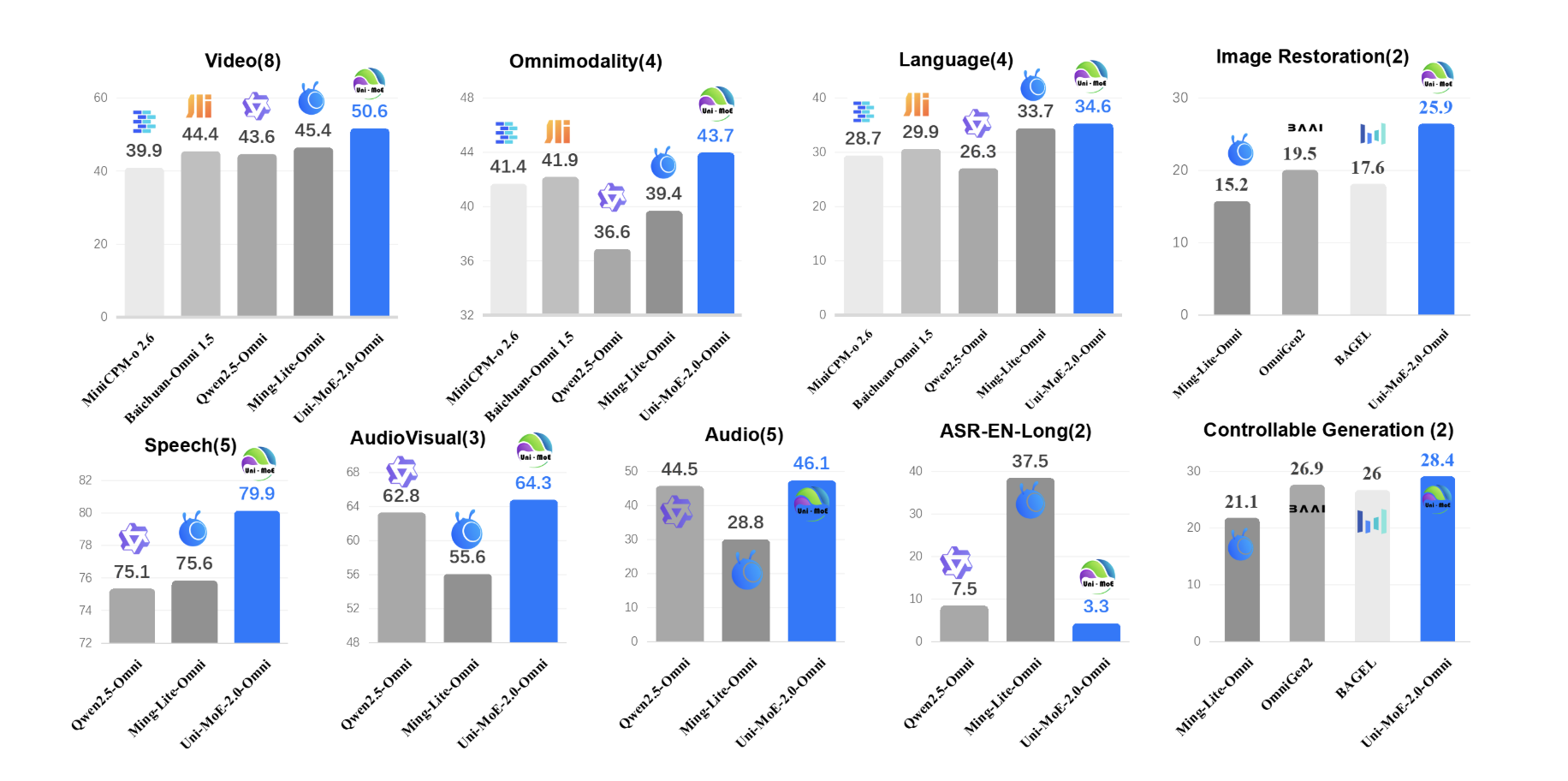
How do you build one open model that can reliably understand text, images, audio and video while still running efficiently? A team of researchers from Harbin Institute of Technology, Shenzhen introduced Uni-MoE-2.0-Omni, a fully open omnimodal large model that pushes Lychee’s Uni-MoE line toward language centric multimodal reasoning. The system is trained from scratch on […] The post Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video Understanding appeared first on MarkTechPost .

The S&P 500 is narrow, but not one-dimensional

‘Parasocial’ crowned Cambridge Dictionary’s word of the year as ‘unhealthy’ relationships with celebrities rise If you’re wondering why Taylor Swift didn’t respond to your social media post offering congratulations on her engagement , then Cambridge Dictionary has a word for you: parasocial. Defined as “involving or relating to a connection that someone feels between themselves and a famous person they do not know”, parasocial has been chosen by the dictionary as its word of the year, as people turn to chatbots, influencers and celebrities to feel connection in their online lives. Continue reading...

Which? study of ChatGPT, Copilot and others uncovers incorrect and misleading tips on investments, tax and insurance Artificial intelligence chatbots are giving inaccurate money tips, offering British consumers misleading tax advice and suggesting they buy unnecessary travel insurance, research has revealed. Tests on the most popular chatbots found Microsoft’s Copilot and ChatGPT advised breaking HMRC investment limits on Isas; ChatGPT wrongly said it was mandatory to have travel insurance to visit most EU countries; and Meta’s AI gave incorrect information about how to claim compensation for delayed flights. Continue reading...

Also in this newsletter: Italy redoubles Ukraine support

Nvidia-Backed Cassava Pushes to Expand AI Access Across Africa Bloomberg.com

The EU is under US pressure to unravel its hard-won online safety laws. We must not give in Protecting our digital sovereignty is crucial. The challenge is why European decision makers are meeting in Berlin on Tuesday at the behest of the German chancellor, Friedrich Merz, and the French president, Emmanuel Macron. As individuals, we spend four to five hours a day accessing the internet via our smartphones and other devices, from social networks to online shopping to AI assistants. It is essential, therefore, that we have control over how the digital space is organised, structured and regulated. Europe has already set to work. Between 2022 and 2024, EU digital laws were adopted by an overwhelming majority of MEPs and unanimously by all member states. The Digital Services Act, the Digital Markets Act, the Data Act and the AI Act form the common foundation protecting our children, citizens, businesses and democracies from all kinds of abuses in the information space. These four major laws mirror our core values and the principles of the rule of law. They make up the most advanced digital legal framework in the world. Europe can be proud of it. Thierry Breton was the European commissioner for the internal market and digital affairs until September 2024 and is a former minister for the economy and finance in France Continue reading...

As GenAI becomes the primary way to find information, local and traditional wisdom is being lost. And we are only beginning to realise what we’re missing This article was originally published as ‘Holes in the web’ on Aeon.co A few years back, my dad was diagnosed with a tumour on his tongue – which meant we had some choices to weigh up. My family has an interesting dynamic when it comes to medical decisions. While my older sister is a trained doctor in western allopathic medicine, my parents are big believers in traditional remedies. Having grown up in a small town in India, I am accustomed to rituals. My dad had a ritual, too. Every time we visited his home village in southern Tamil Nadu, he’d get a bottle of thick, pungent, herb-infused oil from a vaithiyar , a traditional doctor practising Siddha medicine. It was his way of maintaining his connection with the kind of medicine he had always known and trusted. Dad’s tumour showed signs of being malignant, so the hospital doctors and my sister strongly recommended surgery. My parents were against the idea, worried it could affect my dad’s speech. This is usually where I come in, as the expert mediator in the family. Like any good millennial, I turned to the internet for help in guiding the decision. After days of thorough research, I (as usual) sided with my sister and pushed for surgery. The internet backed us up. Continue reading...

Introducing a custom model for understanding privileged roles in Microsoft Entra ID, developed by TrustedSecWhenever our team conducts a Hardening Review of Microsoft Entra, 365, or Azure, we always emphasize protecting…

arXiv:2511.10540v2 Announce Type: replace-cross Abstract: Drift chambers have long been central to collider tracking, but future machines like a Higgs factory motivate higher granularity and cluster counting for particle ID, posing new data processing challenges. Machine learning (ML) at the "edge", or in cell-level readout, can dramatically reduce the off-detector data rate for high-granularity drift chambers by performing cluster counting at-source. We present machine learning algorithms for cluster counting in real-time readout of future drift chambers. These algorithms outperform traditional derivative-based techniques based on achievable pion-kaon separation. When synthesized to FPGA resources, they can achieve latencies consistent with real-time operation in a future Higgs factory scenario, thus advancing both R&D for future collider detectors as well as hardware-based ML for edge applications in high energy physics.
Don't Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
arXiv:2511.10492v2 Announce Type: replace-cross Abstract: Optimizing recommender systems for objectives beyond accuracy, such as diversity, novelty, and personalization, is crucial for long-term user satisfaction. To this end, industrial practitioners have accumulated vast amounts of structured domain knowledge, which we term human priors (e.g., item taxonomies, temporal patterns). This knowledge is typically applied through post-hoc adjustments during ranking or post-ranking. However, this approach remains decoupled from the core model learning, which is particularly undesirable as the industry shifts to end-to-end generative recommendation foundation models. On the other hand, many methods targeting these beyond-accuracy objectives often require architecture-specific modifications and discard these valuable human priors by learning user intent in a fully unsupervised manner. Instead of discarding the human priors accumulated over years of practice, we introduce a backbone-agnostic framework that seamlessly integrates these human priors directly into the end-to-end training of generative recommenders. With lightweight, prior-conditioned adapter heads inspired by efficient LLM decoding strategies, our approach guides the model to disentangle user intent along human-understandable axes (e.g., interaction types, long- vs. short-term interests). We also introduce a hierarchical composition strategy for modeling complex interactions across different prior types. Extensive experiments on three large-scale datasets demonstrate that our method significantly enhances both accuracy and beyond-accuracy objectives. We also show that human priors allow the backbone model to more effectively leverage longer context lengths and larger model sizes.
arXiv:2511.09287v2 Announce Type: replace-cross Abstract: Current AI training methods align models with human values only after their core capabilities have been established, resulting in models that are easily misaligned and lack deep-rooted value systems. We propose a paradigm shift from "model training" to "model raising", in which alignment is woven into a model's development from the start. We identify several key components for this paradigm, all centered around redesigning the training corpus: reframing training data from a first-person perspective, recontextualizing information as lived experience, simulating social interactions, and scaffolding the ordering of training data. We expect that this redesign of the training corpus will lead to an early commitment to values from the first training token onward, such that knowledge, skills, and values are intrinsically much harder to separate. In an ecosystem in which large language model capabilities start overtaking human capabilities in many tasks, this seems to us like a critical need.
arXiv:2511.06852v3 Announce Type: replace-cross Abstract: Safety alignment instills in Large Language Models (LLMs) a critical capacity to refuse malicious requests. Prior works have modeled this refusal mechanism as a single linear direction in the activation space. We posit that this is an oversimplification that conflates two functionally distinct neural processes: the detection of harm and the execution of a refusal. In this work, we deconstruct this single representation into a Harm Detection Direction and a Refusal Execution Direction. Leveraging this fine-grained model, we introduce Differentiated Bi-Directional Intervention (DBDI), a new white-box framework that precisely neutralizes the safety alignment at critical layer. DBDI applies adaptive projection nullification to the refusal execution direction while suppressing the harm detection direction via direct steering. Extensive experiments demonstrate that DBDI outperforms prominent jailbreaking methods, achieving up to a 97.88\% attack success rate on models such as Llama-2. By providing a more granular and mechanistic framework, our work offers a new direction for the in-depth understanding of LLM safety alignment.
arXiv:2511.06838v3 Announce Type: replace-cross Abstract: The substantial memory bandwidth and computational demands of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, existing high-precision (e.g., FP16) PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for LLM inference using hybrid numerical formats. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator for P3-LLM, featuring enhanced compute units to support hybrid numerical formats. Our careful choice of numerical formats allows to co-design low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Evaluation on a diverse set of representative LLMs and tasks demonstrates that P3-LLM achieves state-of-the-art accuracy in terms of both KV-cache quantization and weight-activation quantization. Combining the proposed quantization scheme with PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over the state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Our quantization code is available at https://github.com/yc2367/P3-LLM.git
arXiv:2511.04376v2 Announce Type: replace-cross Abstract: Music editing has emerged as an important and practical area of artificial intelligence, with applications ranging from video game and film music production to personalizing existing tracks according to user preferences. However, existing models face significant limitations, such as being restricted to editing synthesized music generated by their own models, requiring highly precise prompts, or necessitating task-specific retraining, thus lacking true zero-shot capability. leveraging recent advances in rectified flow and diffusion transformers, we introduce MusRec, a zero-shot text-to-music editing model capable of performing diverse editing tasks on real-world music efficiently and effectively. Experimental results demonstrate that our approach outperforms existing methods in preserving musical content, structural consistency, and editing fidelity, establishing a strong foundation for controllable music editing in real-world scenarios.
A Dynamic Recurrent Adjacency Memory Network for Mixed-Generation Power System Stability Forecasting
arXiv:2511.03746v3 Announce Type: replace-cross Abstract: Modern power systems with high penetration of inverter-based resources exhibit complex dynamic behaviors that challenge the scalability and generalizability of traditional stability assessment methods. This paper presents a dynamic recurrent adjacency memory network (DRAMN) that combines physics-informed analysis with deep learning for real-time power system stability forecasting. The framework employs sliding-window dynamic mode decomposition to construct time-varying, multi-layer adjacency matrices from phasor measurement unit and sensor data to capture system dynamics such as modal participation factors, coupling strengths, phase relationships, and spectral energy distributions. As opposed to processing spatial and temporal dependencies separately, DRAMN integrates graph convolution operations directly within recurrent gating mechanisms, enabling simultaneous modeling of evolving dynamics and temporal dependencies. Extensive validations on modified IEEE 9-bus, 39-bus, and a multi-terminal HVDC network demonstrate high performance, achieving 99.85%, 99.90%, and 99.69% average accuracies, respectively, surpassing all tested benchmarks, including classical machine learning algorithms and recent graph-based models. The framework identifies optimal combinations of measurements that reduce feature dimensionality by 82% without performance degradation. Correlation analysis between dominant measurements for small-signal and transient stability events validates generalizability across different stability phenomena. DRAMN achieves state-of-the-art accuracy while providing enhanced interpretability for power system operators, making it suitable for real-time deployment in modern control centers.
arXiv:2510.22540v2 Announce Type: replace-cross Abstract: Clustering on NISQ hardware is constrained by data loading and limited qubits. We present \textbf{qc-kmeans}, a hybrid compressive $k$-means that summarizes a dataset with a constant-size Fourier-feature sketch and selects centroids by solving small per-group QUBOs with shallow QAOA circuits. The QFF sketch estimator is unbiased with mean-squared error $O(\varepsilon^2)$ for $B,S=\Theta(\varepsilon^{-2})$, and the peak-qubit requirement $q_{\text{peak}}=\max\{D,\lceil \log_2 B\rceil + 1\}$ does not scale with the number of samples. A refinement step with elitist retention ensures non-increasing surrogate cost. In Qiskit Aer simulations (depth $p{=}1$), the method ran with $\le 9$ qubits on low-dimensional synthetic benchmarks and achieved competitive sum-of-squared errors relative to quantum baselines; runtimes are not directly comparable. On nine real datasets (up to $4.3\times 10^5$ points), the pipeline maintained constant peak-qubit usage in simulation. Under IBM noise models, accuracy was similar to the idealized setting. Overall, qc-kmeans offers a NISQ-oriented formulation with shallow, bounded-width circuits and competitive clustering quality in simulation.
arXiv:2510.17067v2 Announce Type: replace-cross Abstract: Regret matching (RM) -- and its modern variants -- is a foundational online algorithm that has been at the heart of many AI breakthrough results in solving benchmark zero-sum games, such as poker. Yet, surprisingly little is known so far in theory about its convergence beyond two-player zero-sum games. For example, whether regret matching converges to Nash equilibria in potential games has been an open problem for two decades. Even beyond games, one could try to use RM variants for general constrained optimization problems. Recent empirical evidence suggests that they -- particularly regret matching$^+$ (RM$^+$) -- attain strong performance on benchmark constrained optimization problems, outperforming traditional gradient descent-type algorithms. We show that RM$^+$ converges to an $\epsilon$-KKT point after $O_\epsilon(1/\epsilon^4)$ iterations, establishing for the first time that it is a sound and fast first-order optimizer. Our argument relates the KKT gap to the accumulated regret, two quantities that are entirely disparate in general but interact in an intriguing way in our setting, so much so that when regrets are bounded, our complexity bound improves all the way to $O_\epsilon(1/\epsilon^2)$. From a technical standpoint, while RM$^+$ does not have the usual one-step improvement property in general, we show that it does in a certain region that the algorithm will quickly reach and remain in thereafter. In sharp contrast, our second main result establishes a lower bound: RM, with or without alternation, can take an exponential number of iterations to reach a crude approximate solution even in two-player potential games. This represents the first worst-case separation between RM and RM$^+$. Our lower bound shows that convergence to coarse correlated equilibria in potential games is exponentially faster than convergence to Nash equilibria.
arXiv:2510.12487v2 Announce Type: replace-cross Abstract: Reliable handling of code diffs is central to agents that edit and refactor repositories at scale. We introduce Diff-XYZ, a compact benchmark for code-diff understanding with three supervised tasks: apply (old code $+$ diff $\rightarrow$ new code), anti-apply (new code $-$ diff $\rightarrow$ old code), and diff generation (new code $-$ old code $\rightarrow$ diff). Instances in the benchmark are triples $\langle \textit{old code}, \textit{new code}, \textit{diff} \rangle$ drawn from real commits in CommitPackFT, paired with automatic metrics and a clear evaluation protocol. We use the benchmark to do a focused empirical study of the unified diff format and run a cross-format comparison of different diff representations. Our findings reveal that different formats should be used depending on the use case and model size. For example, representing diffs in search-replace format performs best for larger models across most tasks, while structured udiff variants offer similar but slightly weaker performance. In contrast, smaller open models benefit little from any formatting choice. The Diff-XYZ benchmark is a reusable foundation for assessing and improving diff handling in LLMs that can aid future development of diff formats and models editing code. The dataset is published on HuggingFace Hub: https://huggingface.co/datasets/JetBrains-Research/diff-xyz.